
 关于提示词
关于提示词
# 出图流程
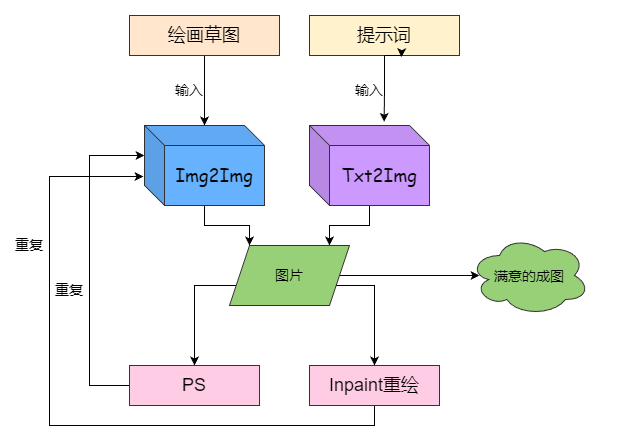
出图迭代,有循环迭代和线性迭代两种,线性迭代适用于多样性测试,而 循环迭代 是优化的更好选择。
来回改提示 + 固定种子并不是好选择。
出好图基本方向就是:
- 提示词 + PS/Inpaint(微修/嫁接)
- 提示词 + 3D 参考
# tag思路
# 先看一些tag辅助工具
- Danbooru: https://danbooru.donmai.us/wiki_pages/tag_groups
- Danbooru标签超市: https://tags.novelai.dev/ (opens new window)
标签超市github: https://github.com/wfjsw/danbooru-diffusion-prompt-builder (opens new window) - 元素法典: https://docs.qq.com/doc/DWHl3am5Zb05QbGVs (opens new window)
StableDiffusion-web-ui里的tag辅助插件
- 标签补全插件: https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/blob/main/README_ZH.md
- 标签选择插件: https://github.com/maple-flowers/maple-from-fall-and-flower (opens new window)
# tag种类
- 单词标签
- 自然语言
- Emoji
- 颜文字(仅支持西方颜文字)
- 空格 逗号前后的少量空格并不影响实际效果。 开头和结尾的额外空格会被直接丢弃。词与词之间的额外空格也会被丢弃。
- 标点符号
用逗号、句号、甚至是空字符(\0)来分隔关键词,可以提高图像质量。目前还不清楚哪种类型的标点符号或哪种组合效果最好。当有疑问时,只要以一种使提示更容易被阅读的方式来做。
对于部分模型,建议将下划线(_)转换为空格。 - 艺术风格词
- 运动和姿势
# 自己写tag思路
一、主题,外表,情绪,衣服,姿势,背景 一类
二、画面质量,风格,主体(外表,情绪,衣服),场景,...
1、画面质量(通用tag)
- 一般用master,best quality,official art
2、画面的风格(绘画风格、构图方式等)
- 例如CG 壁纸,line art (线条,线稿,素描)或指向性的风格:例如原神、明日方舟等
3、画面主体(人物、物体的细节描述)
- 画面主体
- 特定角色: 阿提拉 (Fate)、弑神者系列、恶魔焰 (魔法少女小圆
- 创作人物tag步骤
- a.人物的上半身或者全身
- f.人物的表情、动作
- b.人物的数量、性别
- g.人物的衣服鞋子款式
- h.人物的袜子、
- c.人物的眼睛、头发颜色
- d.人物头发的发型、发饰
- e.人物的年龄、身高、胸围
- i.人物的装饰
4、画面场景(环境、点缀等细节描述) 画面场景:所处环境,比如白天、黑夜、太阳、月亮森林、海边、城市等等
5、其他 (视角、特色描述等)
- 视角,比如从下往上看、专注脸部、树叶飘落、流星等等
# tag语法
- 大小写
但CLIP 的标记器在标记之前会将所有单词转为小写。其他模型,如 BERT 和 T5,将大写的单词与非大写的单词区别对待。 应避免涉及特殊语法,以防被解释为其他语义,例如AND;
总结:尽量用小写
词汇顺序
理论上后面的提示词不应该比前面的提示词更有影响,也就是越重要的提示词放越前面。 但实际上解析器理解事物的方式是不透明的,因此没有办法确切地知道词法顺序是否具有“锚”效应。长度
避免过长的提示词。特异性
最好不要出有现广泛含义的关键词;比如"大","小","动漫"这样的。
一个关键词有非常具体的含义是最好的。权重系数 Wiki:Attention Emphasis (opens new window)
对于 SD-WebUI,具体规则如下:
- (word) - 将权重提高 1.1 倍
- ((word)) - 将权重提高 1.21 倍(= 1.1 * 1.1),乘法的关系。
- [word] - 将权重降低 90.91%
- (word:1.5) - 将权重提高 1.5 倍
- (word:0.25) - 将权重减少为原先的 25%
- (word) - 在提示词中使用字面意义上的 () 字符
使用数字指定权重时,必须使用 () 括号。如果未指定数字权重,则假定为 1.1。指定单个权重仅适用于 SD-WebUI。
权重增加通常会占一个提示词位,应当避免加特别多括号。
无论使用何种具体的脚本,重复某个关键词似乎都会增加其效果。
标签替换 Prompt Editing (opens new window)
允许您开始先使用一个提示词,但在生成过程中间切换到其他提示词。基本语法是:
- [to:when] 在指定数量的 step 后添加 to 到提示
- [from::when] 在指定数量的 step 后从提示中删除 from
- [from:to:when] 在指定数量的 step 后将 from 替换为 to
其中 from 与 to 是替换前后的提示词,when 表示替换时机。
如果 when 是介于 0 和 1 之间的数字,则它指进行切换的步数的百分比。如果它是一个大于零的整数,那么这代表进行切换的字面步数。
替换标签可无限嵌套。
示例:对于 a [fantasy:cyberpunk:16] landscape 开始时,模型将绘制 a fantasy landscape。 在第 16 步之后,它将采用 a cyberpunk landscape 继续生成。标签轮转 Alternating Words (opens new window)
允许您在生成过程中每步轮换使用多个提示词。基本语法是:
[a|b|c]生成的第一步将使用 a,第二步将使用 b,第三步将使用 c,第四步将使用 a,依此类推。
多组提示词生成 Composable-Diffusion (opens new window)
AND 的语法优先级最高,因此试图使用 AND 分离单个提示词的操作是错误的。注意甄别部分公开教程中的错误示例。
允许在生成时同时使用多组提示词,并将结果直接相加。基本语法是:
a, b, c AND d, e, f这将使用两组提示词 a, b, c 和 d, e, f 生成,并将它们的结果相加。
Prompt matrix 参数矩阵 使用 | 分隔多个 Tag,程序将为它们的每个组合生成一个图像。 例如,如果使用 a busy city street in a modern city|illustration|cinematic lighting ,则可能有四种组合(始终保留提示的第一部分):
- a busy city street in a modern city
- a busy city street in a modern city, illustration
- a busy city street in a modern city, cinematic lighting
- a busy city street in a modern city, illustration, cinematic lighting